

Source Files: Keep Code Local
I think we're going a little overboard with the amount of structure we force into our projects

Back in college, I was taught that modularity and encapsulation were the keys to writing maintainable software—it’s easier to change things if the impact of that change is bounded by the perimeter of a module. That’s hard to argue with; software (or just about anything for that matter) would be impossible to work with if every change we made had a potentially global impact.
But, as with all things, breaking code into modules is not always the right thing to do, at least from the start. Sometimes the simplest way to create something new is to break the rules.
Let’s look at a Rails application as an example. Now, before I get started, I need to say that I’m not picking on Rails here: what I’m about to describe is pretty universal. It’s just that I’m in the middle of converting a fairly large Rails site as I’m writing this, so the issues are fresh in my mind.
The Good and Bad of Conventions
Rails (quite rightly) promises “convention over configuration.” If you put stuff in the right place, with the right name, Rails will find and use it without the need for you to do any knitting. This can be a big time saver. It also means you can look at any Rails project and find your way around: they all look the same.
But, when followed slavishly, these conventions can actually make things more difficult to change, particularly during the early stages of a project. To illustrate this, let’s look at a simple Rails view.
Anatomy of a View
By convention, Rails apps are organized around the idea of resources. Each resource will have a controller, a set of view templates, and most likely a model—it’s an MVC framework. If we have a resource named customer, then the source code of the controller will be inapp/controllers/customers_controller and the view templates will be in the directoryapp/views/customers. In addition, Rails looks for the file app/helpers/customers_helper.rb. The helpers are Ruby methods that you can call in any of the customer templates. Finally, your view might need some CSS and some JavaScript.
That’s five files, widely spread across a directory tree. That’s not a tragedy, but it does slow things down, particularly when you’re first writing the code.
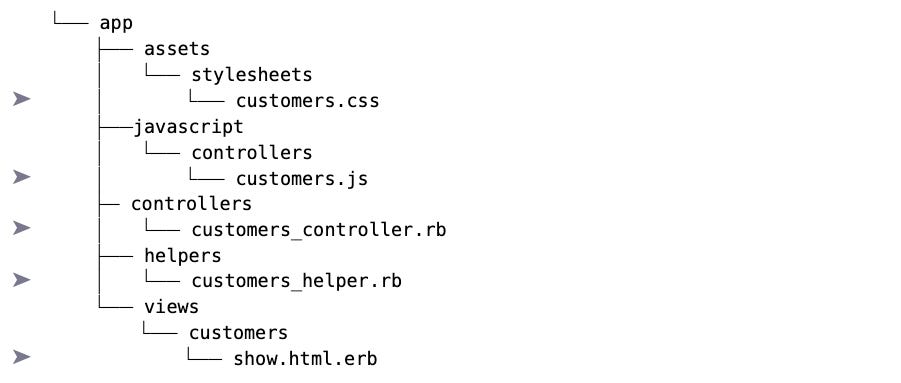
Here’s what I do instead.
Two files: the controller and the view template. The controller code is normally boilerplate, so most of my activity is in the template—that’s where I put all my view code: CSS, JavaScript, helpers, and the template itself.
Here’s what one of those templates looks like:

I start by fleshing out the template. When I find I need some code (often to do with formatting) I just add a function to the helper functions block in the same file. In the rare cases I also need to do some stylin’, I add CSS to the top of the file.
Being able to work in one place without switching back and forth makes my life simple.
Should I find myself needing the same helper function in multiple views, I’ll extract it into a normal xxx_helper.rb file. This doesn’t affect the template.
I can hear some of you saying “we know that’s just wrong. You need to follow the conventions.” Maybe they’re right. But so far I’ve seen no ill effects. If I do, splitting the file will be easy.
I can also hear Elm and React developers saying “You just realized this? We’ve been doing it all along.” Indeed you have; indeed you have. And your success doing so helped convince me that this approach is viable, and not just for view components.
Splitting Regular Source Code
The “keep it local in one file” philosophy doesn’t just apply to Rails views. I use it all the time.
When I’m writing some new code, I typically start out with a single file. I’ll flesh out the outline, which will often involve creating new modules and classes. I’ll just put them in that same file. As the code starts to take shape, I’ll add more modules, again all in that one file. Why? Because it is so much simpler to refactor as I experiment with alternative structures. Moving code around, renaming things, and even just searching for things is easier.
When I get to the point where it’s stable, I step back and look at the whole thing. I ask myself: when I come back to this in six months, how hard will it be to pick it back up when it’s all one piece? Often I just leave it. But just as often I’ll split it into separate source files, often in a subdirectory. In addition, the second I want to share functionality from that code to some other module, I’ll likely split the code I’m sharing out into its own file. Doing so reduces the dependency footprint, and therefore ties that other module to less of the original code.
That’s Cwazy Talk!
If I’d read this article five or ten years ago, I’d have labeled the author a troll and moved on. But now I honestly feel this is a great way to create code.
Start with the code in a single file, and keep it there while you’re making lots of changes. When it is stable, maybe break it into individual files. But be sure you know why you’re making that split.
Try It Before You Dismiss It
Are you working in an environment where code is split across multiple files by convention? Would things break if you tried starting with everything in a single file?
Perhaps try it. If you’re on a team, and don’t want them to beat you up about your radical code organization, just use the technique locally as you create new functionality. Then, before you push your changes, you can split your single file into many.
Along the way, see if the single file solution makes things simpler. If so, perhaps mention it to your team, and see if they’d like to experiment, too.
Even if they do not, if the technique works for you, use it.
And let me know what you think below.
Lately I'm finding that "grow then split" as opposed to "split then grow" can be applied all around, in code, requirements, teams inside an organization, how I structure files in Obsidian, etc. I really like that heuristic.
The earliest source I know for this idea is "The Timeless Way of Building" (which I haven't fully read yet):
> Within this process, every individual act of building is a process in which space gets differentiated. It is not a process of addition, in which preformed parts are combined to create a whole, but a process of unfolding, like the evolution of an embryo, in which the whole precedes the parts, and actually gives birth to them, by splitting.